Troubleshooting High Availability¶
High availability configurations can be complex, and with numerous different ways to configure a failover cluster, it can be tricky to get things working properly. This section discusses common problems and solutions for the majority of cases. If issues are still present after consulting this section, there is a dedicated HA/CARP/VIPs board on the Netgate Forum.
Before proceeding, take the time to check all members of the HA cluster to ensure that they have consistent configurations. Often, it helps to walk through the example setup, double-checking all the proper settings. Repeat the process on the secondary node, and watch for any places where the configuration must be different on the secondary. Be sure to check the CARP status (Check CARP status) and ensure CARP is enabled on all cluster members.
Errors relating to HA will be logged in Status > System Logs, on the System tab. Check those logs on each system involved to see if there are any messages relating to XMLRPC sync, CARP state transitions, or other related errors.
See also
The issues on this page are for HA in general. For issues specific to using HA in virtual environments, see Troubleshooting High Availability Clusters in Virtual Environments
Common Misconfigurations¶
There are several common misconfigurations that happen which prevent HA from working properly.
Incorrect Interface Order¶
As mentioned on pfSense Software XMLRPC Config Sync Overview, the interface assignment order and internal identifiers must match identically on both nodes.
If the interface order does not match, the configuration synchronization process will copy rules and other settings such as DHCP failover to different/unexpected interfaces on the secondary node.
Use a different VHID on each CARP VIP¶
Every CARP VIP on a given interface or broadcast domain must use a different VHID. The VHID determines the virtual MAC address used by a CARP IP address, thus different clusters attempting to use the same VHID on the same L2 segment cause a MAC address conflict.
Within a single HA pair, input validation prevents configuring duplicate VHIDs. Unfortunately, it isn’t always that simple. CARP is a multicast technology, and as such anything using CARP on the same network segment must use a unique VHID, even if it is a different subnet. Other protocols such as VRRP and HSRP also use protocols similar enough to CARP that they can conflict, so ensure there are no other devices using similar VHIDs with other protocols, such as if the ISP or another router on the local network is using VRRP.
The best way around this is to use a unique set of VHIDs. If a known-safe private network is in use, start numbering at 1. On a network where VRRP or CARP are conflicting, consult with the administrator of that network to find a free block of VHIDs. Performing a packet capture on the segment and analyzing it with tools such as Wireshark may also reveal other hosts sending similar multicast messages with IDs to avoid.
Incorrect CARP VIP Settings¶
Inspect the settings for CARP VIPs (Firewall > Virtual IPs) to ensure they are correct and consistent on both nodes.
The Advertising Frequency values must be appropriate for each VIP and node:
- Base:
Values should be the same on both nodes. In some situations where the secondary node is on a slow or non-local link, users have increased this value on only the secondary, but that can lead to problems with each node assuming their expected roles at the proper times.
- Skew:
Values must be different on the primary and secondary nodes. The primary is typically
1or0, and the secondary is typically100.
Incorrect Times¶
Check that all nodes involved are properly synchronizing their clocks using NTP and have valid time zones, especially if running in a Virtual Machine. If the clocks are too far apart, some synchronization tasks like DHCP failover will not work properly.
Incorrect Subnet Mask¶
The real subnet mask must be used for a CARP VIP, not /32. This
must match the subnet mask for the IP address on the interface to which the
CARP VIP is assigned.
Both Nodes in Maintenance Mode¶
If both nodes have activated Persistent CARP Maintenance Mode at Status >
CARP (failover), they each will advertise a skew of 254 and the actual
status will be unpredictable. Ensure only one node is in maintenance mode at a
time.
Incorrect Hash Error¶
There are a few reasons why this error turns up in the system logs, some more worrisome than others.
If CARP is not working properly when this error is present, it could be due to a configuration mismatch. Ensure that for a given VIP, that the VHID, password, and IP address/subnet mask all match.
If the settings appear to be proper and CARP still does not work while generating this error message, then there may be multiple CARP instances on the same broadcast domain. Disable CARP and monitor the network via packet capturing to check for other CARP or CARP-like traffic (Packet Capturing), then adjust VHIDs appropriately.
If CARP is working properly and this message is in the logs when the node boots up, it may be disregarded. It is normal for this message to be seen during boot, as long as CARP continues to function properly (primary shows MASTER status, secondary shows BACKUP status).
Both Nodes Appear as MASTER¶
This will happen if the secondary node cannot see the CARP heartbeat advertisements from the primary. Check the firewall rules, connectivity between the nodes on that segment, and switch configurations. Also check the system logs for any relevant errors that may lead to a solution. If this is encountered in a Virtual Machine (VM) hypervisor environment such as VMware ESXi, see Troubleshooting High Availability Clusters in Virtual Environments.
Primary Node is Stuck as BACKUP¶
In some cases this may happen normally for a short period after a node comes
back online. However, certain hardware failures or other error conditions can
cause a server to silently take on a high advskew of 240 in order to
signal that it still has a problem and should not become master. This can check
be checked from the GUI, or via the shell or Diagnostics > Command.
In the GUI, this condition is printed in an error message on Status > CARP.
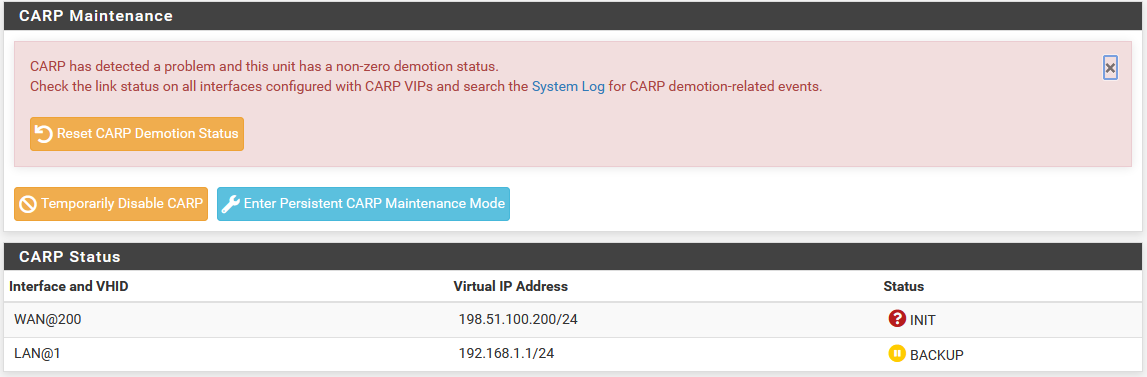
CARP Status when Primary is demoted¶
From the shell or Diagnostics > Command, run the following command to check for a demotion:
# sysctl net.inet.carp.demotion
net.inet.carp.demotion: 240
If the value is greater than 0, the node has demoted itself.
In that case, isolate the firewall, check its network connections, and perform further hardware testing.
If the demotion value is 0 and the primary node still appears to be demoting
itself to BACKUP status, or it is flapping, check the network to ensure
there are no layer 2 loops. If the firewall receives its own heartbeats back
from the switch, it can also trigger a change to BACKUP status.
Other Switch and Layer 2 Issues¶
If the nodes are plugged into separate switches, ensure that the switches are properly trunking and passing broadcast/multicast traffic.
Some switches have broadcast/multicast filtering, limiting, or “storm control” features that can break CARP.
Some switches have broken firmware that can cause features like IGMP Snooping to interfere with CARP.
If a switch on the back of a modem/CPE is use, try a dedicated switch instead. Switches built into routers and other similar CPE devices often do not properly handle CARP traffic. In these cases, plugging the firewalls into a proper switch and then uplinking to the CPE will eliminate problems.
Configuration Synchronization Problems¶
Double-check the following items when problems with configuration synchronization are encountered:
The XMLRPC synchronization user must be configured properly in the user manager. The account must have the “System - HA node sync” privilege. If users are synchronized, the account must be added on both nodes initially, once the first synchronization happens, the primary will copy its entry the secondary.
The password in the configuration synchronization settings on the primary node must match the synchronization user password on the secondary node.
The GUI must be on the same port on all nodes.
The GUI must be using the same protocol (HTTPS or HTTP) on all nodes.
Traffic must be permitted to the GUI port on the interface which handles XMLRPC synchronization traffic.
Verify that only the primary node has configuration synchronization options enabled.
Ensure no IP address is specified in the Synchronize Config to IP on the secondary node.
Ensure the clocks on both nodes are current and are reasonably accurate.
State Synchronization Problems (pfsync)¶
If the State Creator Host IDs do not line up under Status > CARP in the State Synchronization Status section, that can indicate that the states have not been synchronized. The status should include the Filter Host ID of both nodes if states are synchronizing correctly. If the filter host ID has been changed recently, additional values may be in the list until the older states expire.
Ensure that Synchronize States is enabled on both nodes.
Ensure both nodes have the correct Synchronize interface selected.
Ensure the two nodes can communicate directly on the chosen synchronize interface (e.g. Verify with
pingthat they can both reach each other.)Check the firewall logs for blocked traffic using the
pfsyncprotocol. If the traffic is blocked, make sure it is present on the correct interface. If the interface is correct, then adjust the firewall rules to allow the traffic to pass.Ensure the interface assignment order matches.
If state synchronization does not work with Synchronize Peer IP left empty, fill in the Sync interface IP address of each peer on both nodes.
HA and Multi-WAN Troubleshooting¶
If clients have trouble reaching CARP VIPs when using with Multi-WAN, double check that a rule is present like the one mentioned in Firewall Configuration.