Components of a High Availability Cluster¶
Two or more redundant firewalls running pfSense® Plus software are considered a “High Availability Cluster” or “HA Cluster” for short.
Warning
This should not be called a “CARP Cluster”. CARP is only one of several technologies used to achieve High Availability with pfSense software, and in the future CARP could be swapped for a different redundancy protocol.
The only supported High Availability cluster configuration consists of exactly two nodes, which is also the most common configuration in practice. While it is possible to have more than two nodes in a cluster, additional nodes do not provide a significant advantage. Configurations with more than two nodes are not officially supported.
This guide assumes two identical nodes are in use, one acting as the primary node and the other as the secondary node.
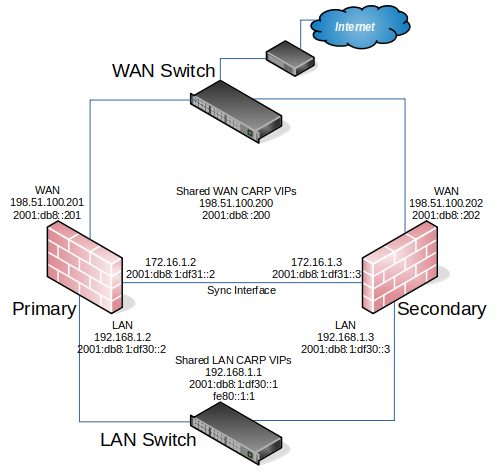
Example High Availability Cluster¶
IP Address Redundancy (CARP)¶
For connectivity through a cluster to continue seamlessly during failover, traffic to and from the cluster must use redundant IP addresses. pfSense® Plus software uses Common Address Redundancy Protocol (CARP) for this task.
A CARP type Virtual IP address (VIP) is shared between nodes of a cluster. CARP refers to the currently active node as the “master”. This node receives traffic sent to the CARP VIP address, and the other nodes sharing the VIP maintain “backup” status and monitor for heartbeats to see if they need to take over the active role. Since only one member of the cluster at a time is using the IP address, there is no IP address conflict between CARP VIPs.
For failover to work properly it is important that inbound traffic coming to the cluster, such as routed upstream traffic, VPNs, NAT, local client gateway, DNS requests, etc., be sent to a CARP VIP and for outgoing traffic such as Outbound NAT to be sent from a CARP VIP. If traffic is addressed to a node directly and not a CARP VIP, then that traffic will not be picked up by other nodes.
CARP works similar to VRRP and HSRP and may even conflict in some cases. Heartbeats are sent out on each interface containing a CARP VIP, one heartbeat per VIP per interface. At the default values for skew and base, each VIP sends out heartbeats about once per second. The skew determines which node is active at a given point in time. Whichever node transmits heartbeats the fastest assumes the active role. A higher skew value causes heartbeats to be transmitted with more delay, so a node with a lower skew will be active unless a network or other issue causes the heartbeats to be delayed or lost.
Note
Never access the firewall GUI, SSH, or other management mechanism using a CARP VIP directly. For management purposes, only use the actual IP address on the interface of each separate node and not the VIP. Otherwise, the client cannot determine beforehand which node it is accessing.
Configuration Synchronization (XMLRPC)¶
Configuration synchronization makes it easier to maintain two nodes which are nearly identical. This synchronization is optional, but maintaining a cluster without it is significantly more work. Without synchronization, administrators would need to make every change multiple times and ensure the changes were consistent.
pfSense® Plus software uses XMLRPC for configuration synchronization. When XMLRPC Synchronization is enabled, the primary node copies settings from compatible areas to the secondary node and activates them after each configuration change.
Certain configuration areas cannot be synchronized, such as the Interface configuration, but most other areas can: Firewall rules, aliases, users, certificates, VPNs, DHCP, routes, gateways, and more. As a general rule, items specific to hardware or a particular installation, such as Interfaces or values under System > General or System > Advanced do not synchronize. The list of compatible areas can vary depending on the version of pfSense software in use. For a list of areas that will synchronize, see the checkbox items on System > High Availability in the XMLRPC section. Most packages will not synchronize, but some contain their own synchronization settings. Consult package documentation for more details.
State Table Synchronization (pfsync)¶
pfSense® Plus software uses pfsync to synchronize firewall state table data between cluster nodes. Changes to the state table on the primary are sent to the secondary nodes over the Sync interface, and vice versa. When State Synchronization is active and properly configured, all nodes have knowledge of every connection flowing through the cluster. If the primary node fails, the secondary node will take over and most clients will not notice the transition since both nodes knew about the connection beforehand.
Failover can still operate without state synchronization, but it will not be seamless. Without state synchronization, if a node fails and another takes over, user connections are dropped. Users may immediately reconnect through the other node, but they would be disrupted during the transition. Depending on the usage in a particular environment, this may go unnoticed, or it could be a significant, but brief, outage.
DHCP failover with Kea¶
HA clusters which provide addresses to clients using DHCP must have the DHCP service configured for high availability. If both nodes attempt to provide DHCP service without being configured for HA, they conflict and cause unpredictable client behavior. When configured for HA, the nodes coordinate their activity and share lease data, acting as a single server capable of operating from either node if one fails.
The best practice is to use the Kea DHCP backend, which is capable of high availability operation for DHCPv4 and DHCPv6.
See also
Existing HA clusters using the ISC DHCP backend can convert to the Kea DHCP backend by following the conversion guide in the pfSense documentation.